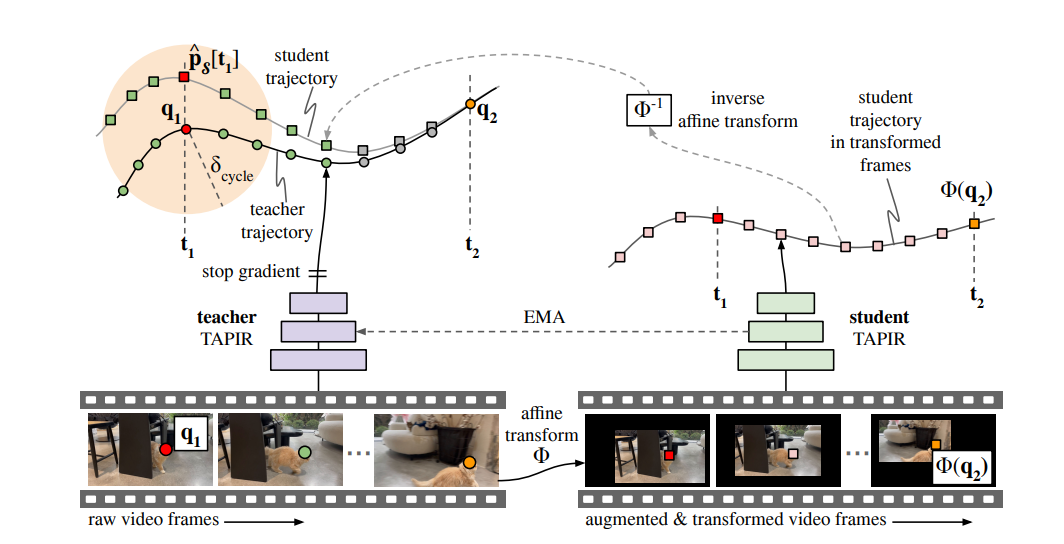
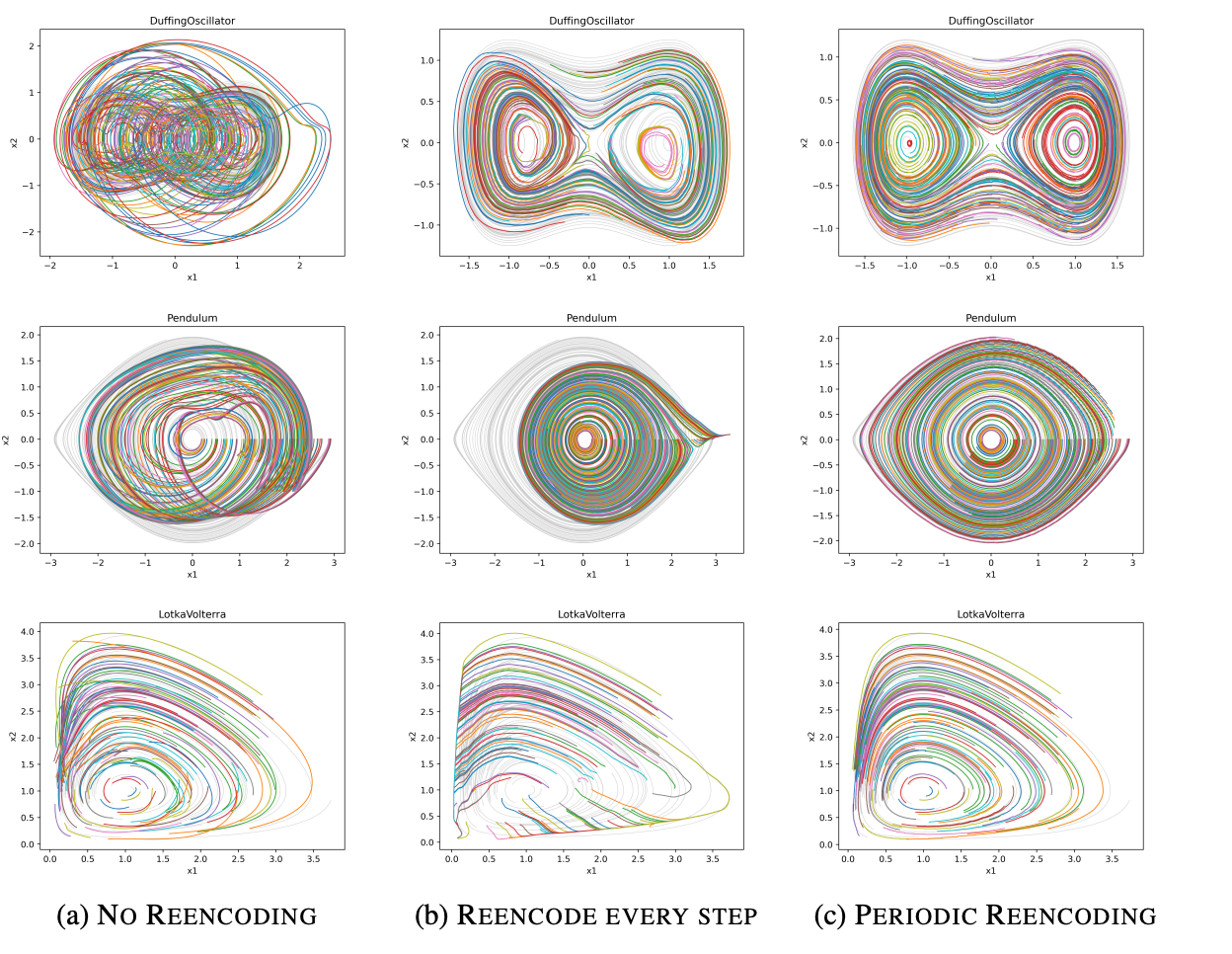
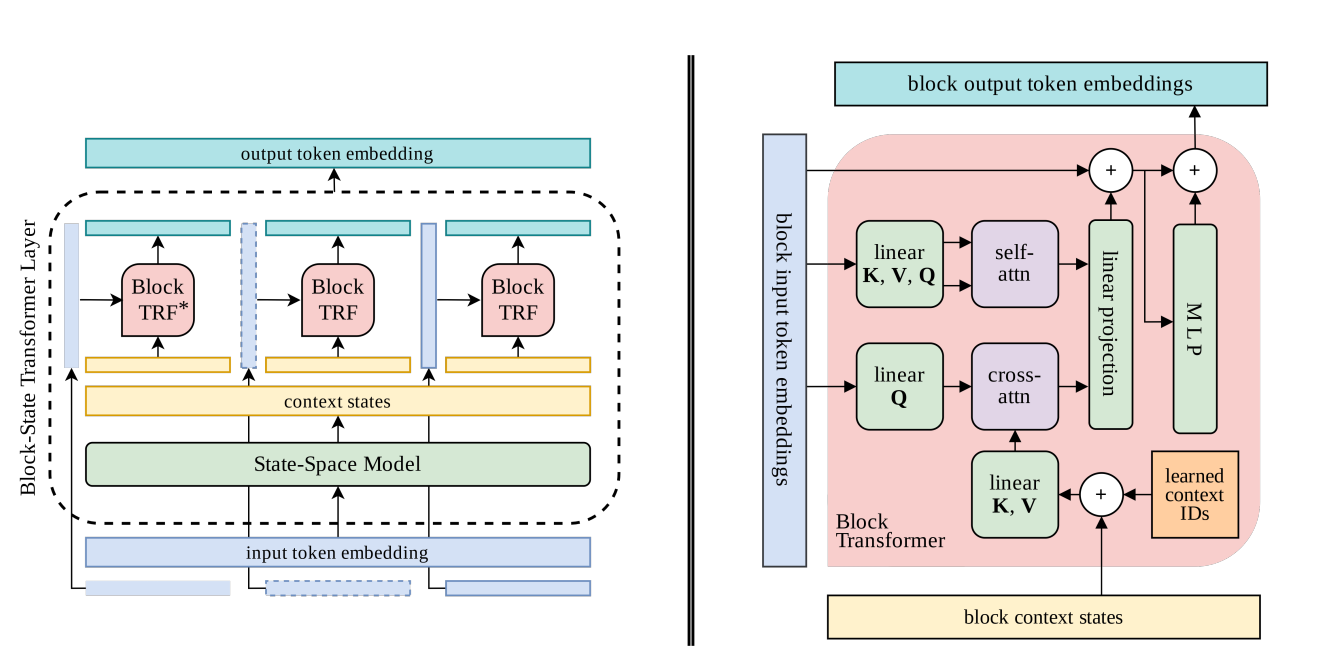
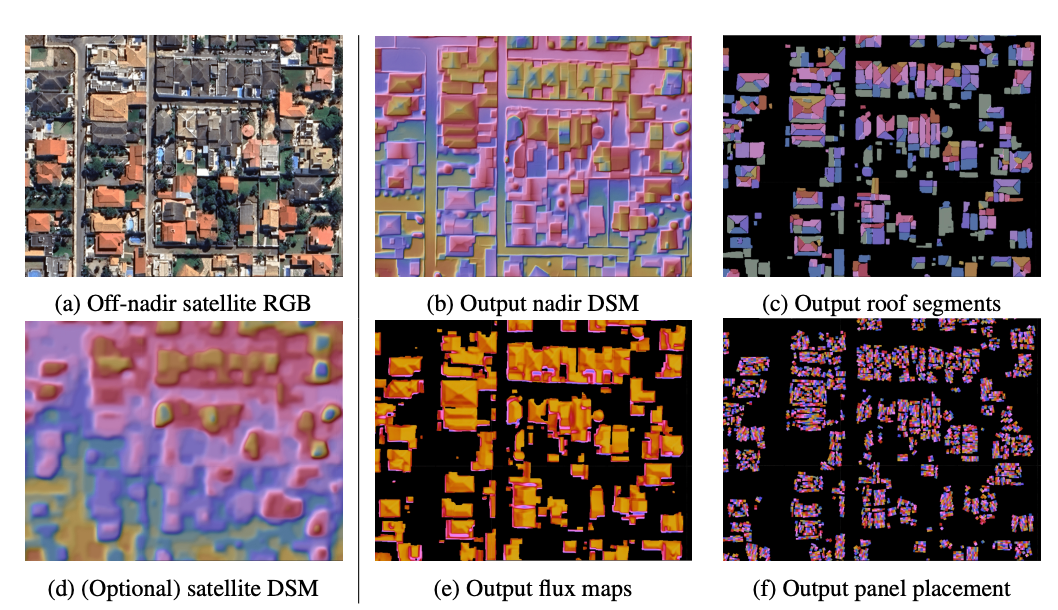
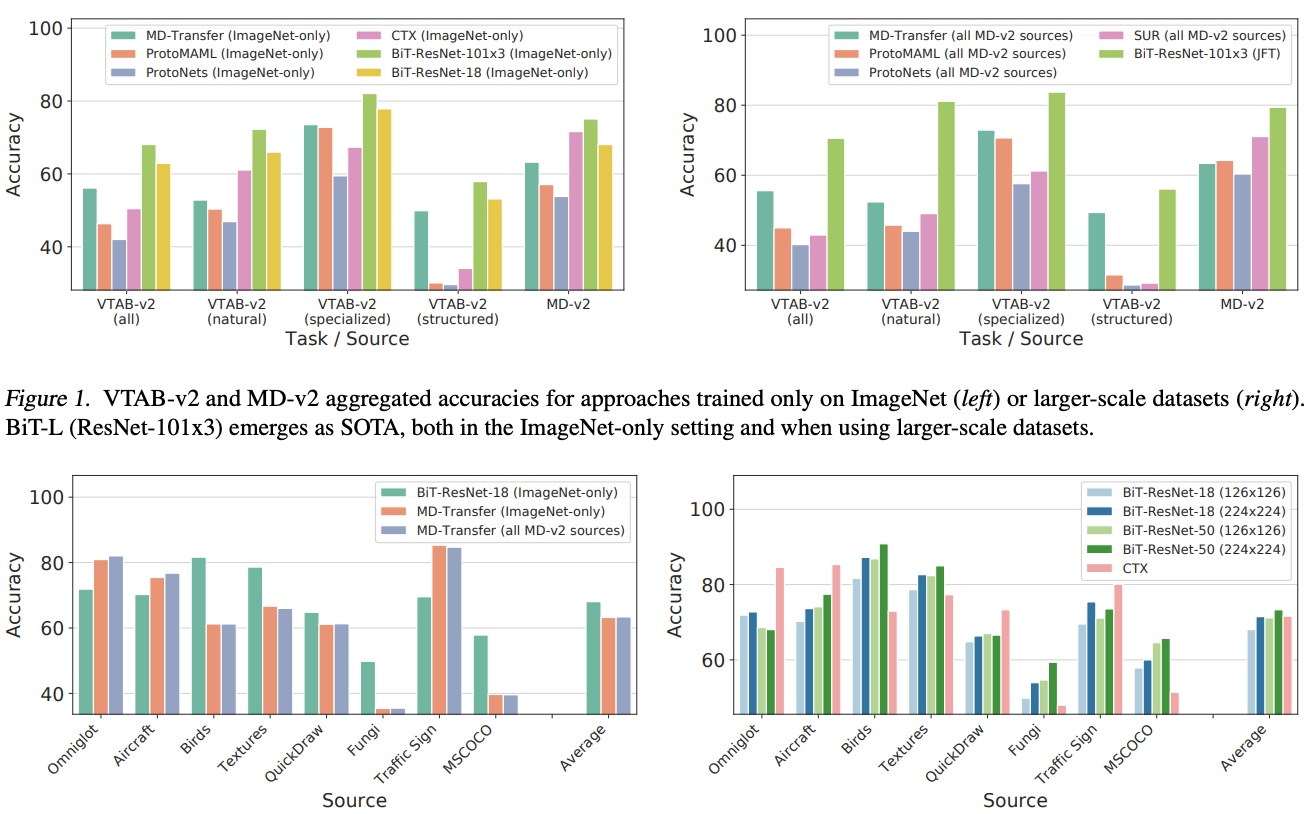
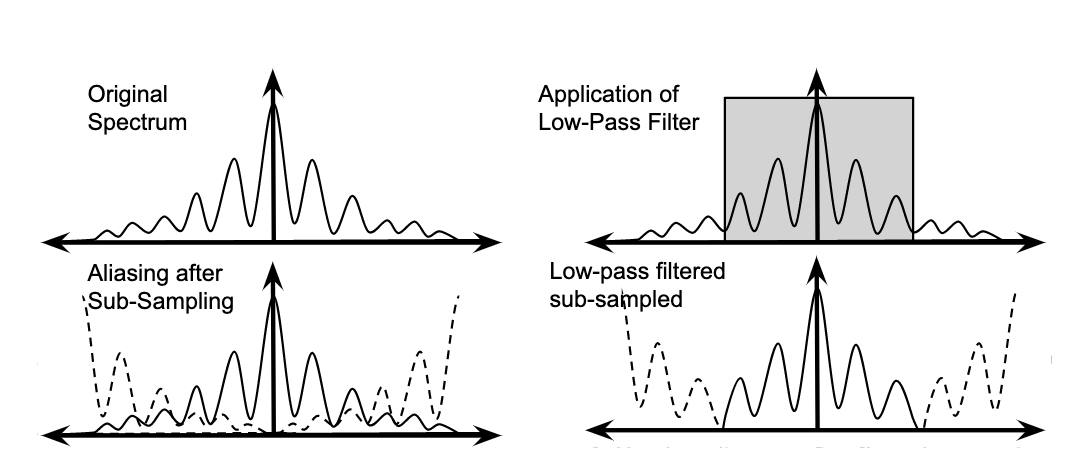
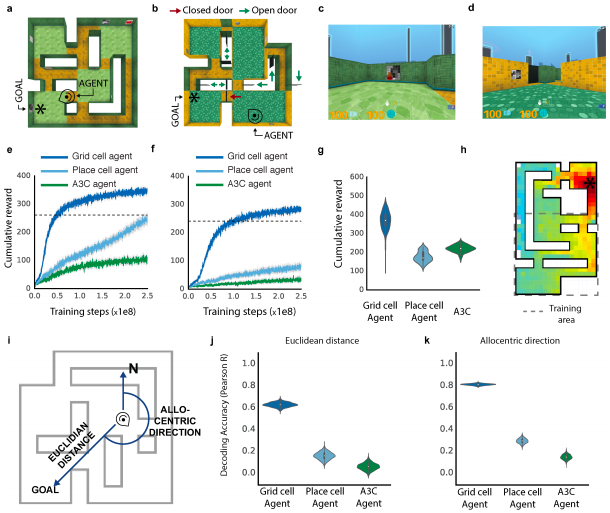
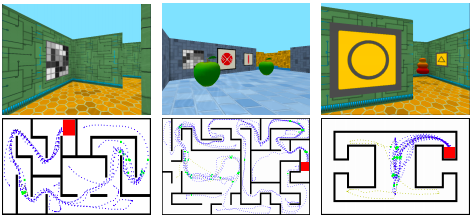
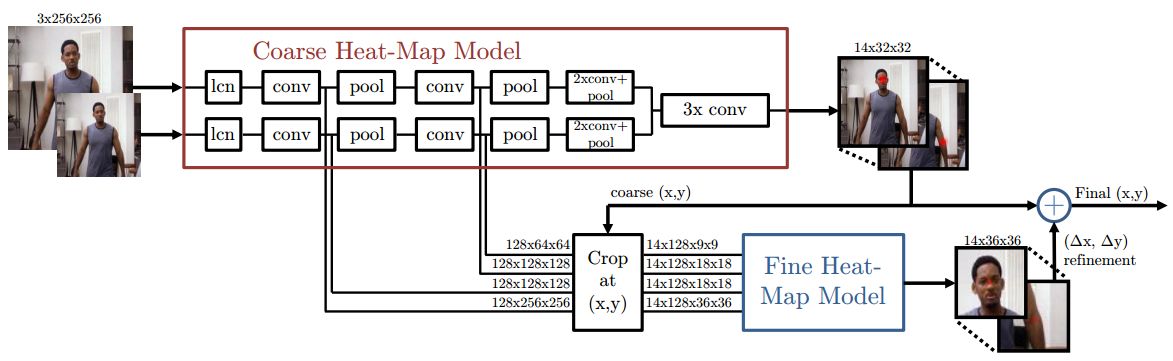
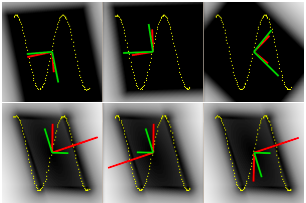
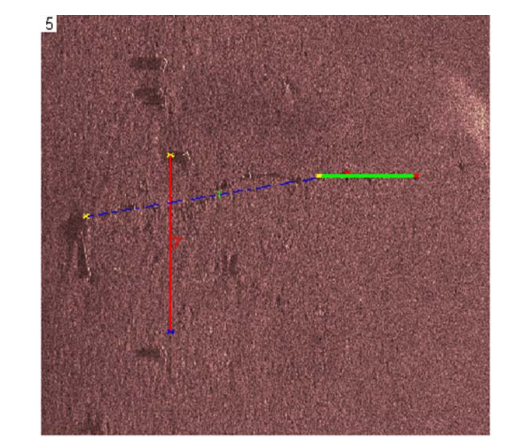
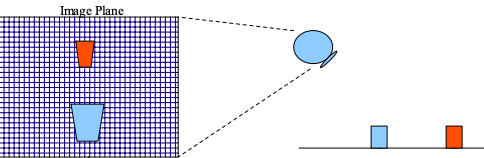
I am a Research Scientist at Google DeepMind, Montreal. I hold a PhD from NYU, where I studied under Yann LeCun, as well as B.Eng. and M.S. degrees in Electrical Engineering from Concordia University and Georgia Tech, respectively. My research focuses on computer vision, self-supervised learning, and optimal control. I am also an adjunct professor in the Department of Computer Science and Operations Research (DIRO) at Université de Montréal and a Core Industry Member at Mila.